Search is often the first experience a user has with your site. Providing a good search experience is vital to the continued success of your product.
Being such a core part of our user experience, it is important that the code supporting our Location Search is flexible, well understood and well documented. Our existing hand rolled solution was poorly understood (the original developer long departed), poorly documented, lacking in unit tests, had slow indexing performance and was missing some pretty key features. Never the less, for all it’s flaws, it worked! Chugging along through location queries without much fuss for many years.
Search is a complex domain shared by many applications. Writing and maintaining our own Search library for such a common problem is a waste. Our problems are not so unique as to not have been faced before. Surely there is a good open-source that we can leverage?
Enter Apache Lucene…
What is Apache Lucene?
Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Or
Google as a Java library
So how does Apache Lucene work?
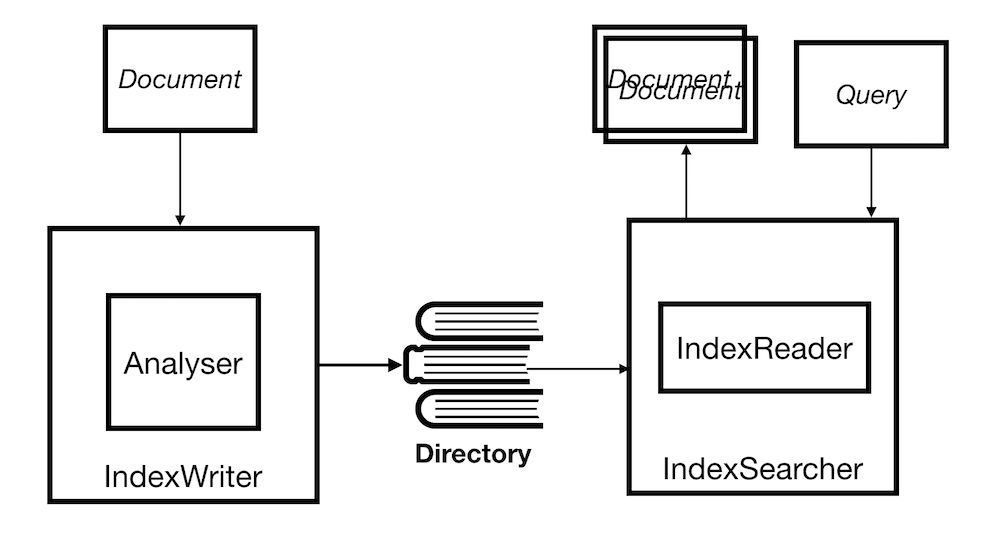
At its core Apache Lucene is just an index, you add documents to that index and you query that index for matching documents. How those documents are written to the index affects what documents come out when you query the index. Documents are analysed before it is written to the index. Analyzers contain different combinations of Tokenizers and Filters which control how what from documents fields end up in the index. A document consists of a collection of fields, different field types are treated differently by the Analyzer. Providing an additional layer of control of how things are indexed.
Apache Lucene provides scalable, high-performance indexing:
- over 600GB/hour on modern hardware
- small RAM requirements – only 1MB heap
- incremental indexing as fast as batch indexing
- index size roughly 20-30% the size of text indexed
and powerful, accurate and efficient search algorithms:
- many powerful query types: phrase queries, wildcard queries, proximity queries, range queries and more
- fielded searching (e.g. title, author, contents), sorting by any field
- multiple-index searching with merged results
- allows simultaneous update and searching
- flexible faceting, highlighting, joins and result grouping
- fast, memory-efficient and typo-tolerant suggesters
- pluggable ranking models, including the Vector Space Model and Okapi BM25
So with all this power how do we find what you are looking for?
Indexing
First you need to organise what you want to search for into documents which can
be added to the index. As each Document is added to the index it goes through
the Analyzer which defines how the document is stored in the index.
Documents
Documents are the unit of indexing and search. A Document is a set of fields, each field has a name, a textual value and a type. How you build the document, effects how that document looks in the index and how it looks when it is returned from the index.
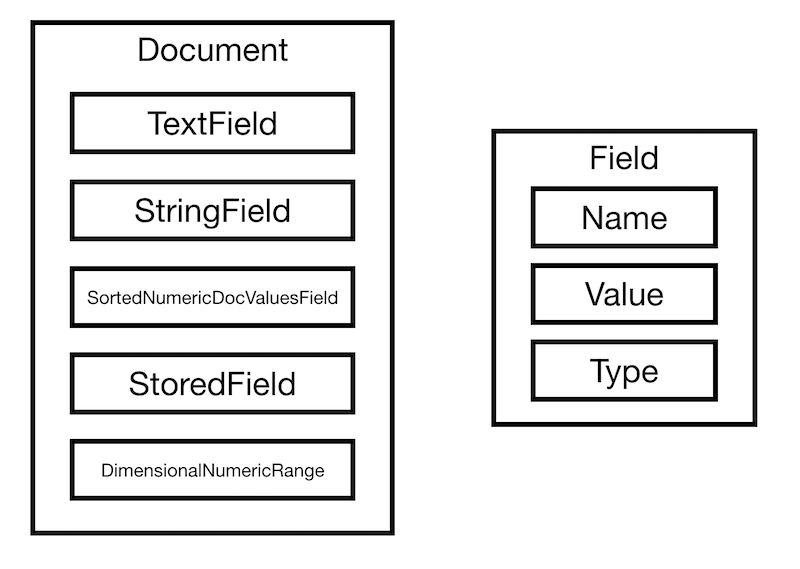
The key to Documents are there fields. The type of field used controls how it
is treated by the Analyzer and, in turn how it is added to the index. A field
has three parts: name, type and value. The value may be text (String, Reader or
pre-analyzed TokenStream), binary (byte[]), or numeric (a Number). Not all fields
are stored when indexed. Fields need to be optionally stored in the index, so
that they may be returned with hits on the document.
For example let’s take 2 of the most common field types:
TextField
A field that is indexed and tokenized, without term vectors.
StringField
A field that is indexed but not tokenized: the entire String value is indexed as a single token. For example this might be used for a ‘country’ field or an ‘id’ field.
Analyzer
From the javadocs:
An Analyzer builds TokenStreams, which analyze text. It thus represents a policy for extracting index terms from text.
An Analyzer consists of Tokenizers and Filters which are combined to
generate Terms which are then added to the index. How the Analyzer treats a
field depends on what type of field is being indexed. From the example above, the
StringField’s value would completely skip the analysis and just add the field
value as a term directly to the index. Where as the value of the TextField
would go through the full analysis pipeline, generating and filtering Tokens
before writing those tokens as Terms to the index.

Apache Lucene comes with an incredible amount of pre-built analysis pipelines in
the analyzers-common
package. For our purpose these proved sufficient but for a detailed breakdown on
how to write your own Analyzer I highly recommend the Toptal’s post
on the matter.
Searching
The search process breaks down into building the query from the term being
searched. Passing that query to the IndexSearcher to be executed giving you a
list of hits. And extracting the resulting documents from the index using those
hits.
Queries
There are 2 ways to build a query:
- By manually instantiating the classes that make up the query. This gives you the most control over how what query is built.
- Or by using Lucene Query Syntax and the
QueryBuuilder. Which you’ve probably encountered if you’ve used any form of Apache Lucene based search engine.
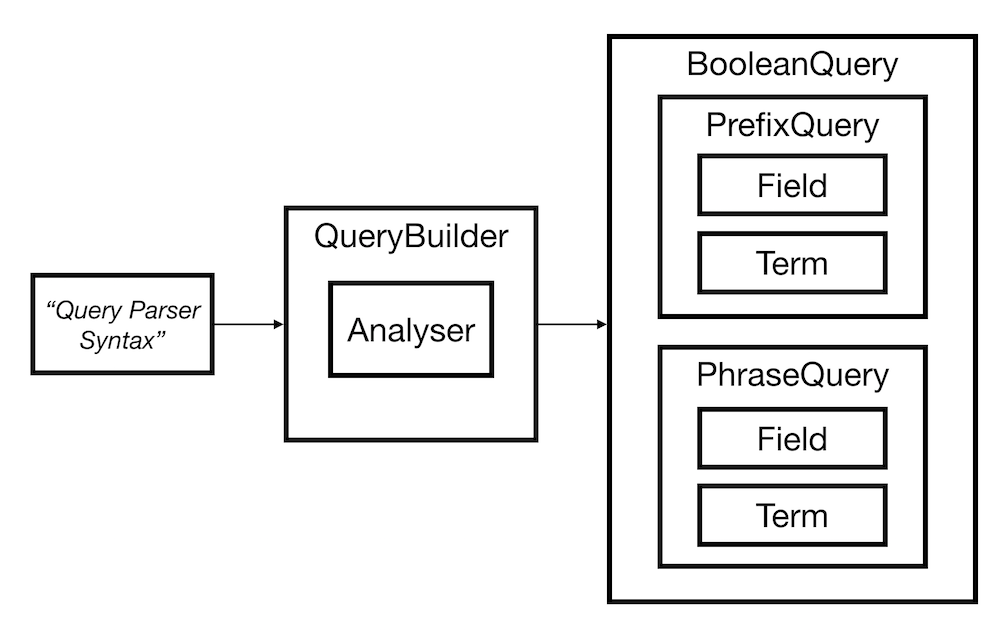
We went for the former as we wanted maximum control over our Query and did not
feel like fighting the query syntax to build the exact query we required.
Now this is where the Analysis comes in, how you’ve indexed your documents has a large affect on how you can query said documents that are now in the index. At the end of the day all Apache Lucene is doing is comparing query terms with terms in the index. So how you’ve analysed your documents controls what terms you can search for.
For Example, lets say you are searching for “Cape Town”. You add “Cape Town” as
the value of a TextField to your Document and you index that document using
the ClassicAnalyzer. You then perform a search for the Term “cape t” and you
get no results back!?
What happened? Well when you added “Cape Town” as the value to your TextField
the Analyzer broke “Cape Town” into 2 separate Terms; “cape” and “town”. Now
when you perform that search for “cape t”, the IndexSearcher is simply
comparing terms. So “cape t” is equal to neither “cape” nor “town”. Tokenisation
is great for providing full-text features but when it comes to providing precise
matches to queries it can complicate matters.
In order to work around this we need to add the value as both a TextField and
StringField so we can get the best of both worlds. When we search “town”, the
term from the TextField will be matched and when we search “cape t” the term
from the StringField will be matched.
Searching
Now that we have our query, let’s perform a search against the index:
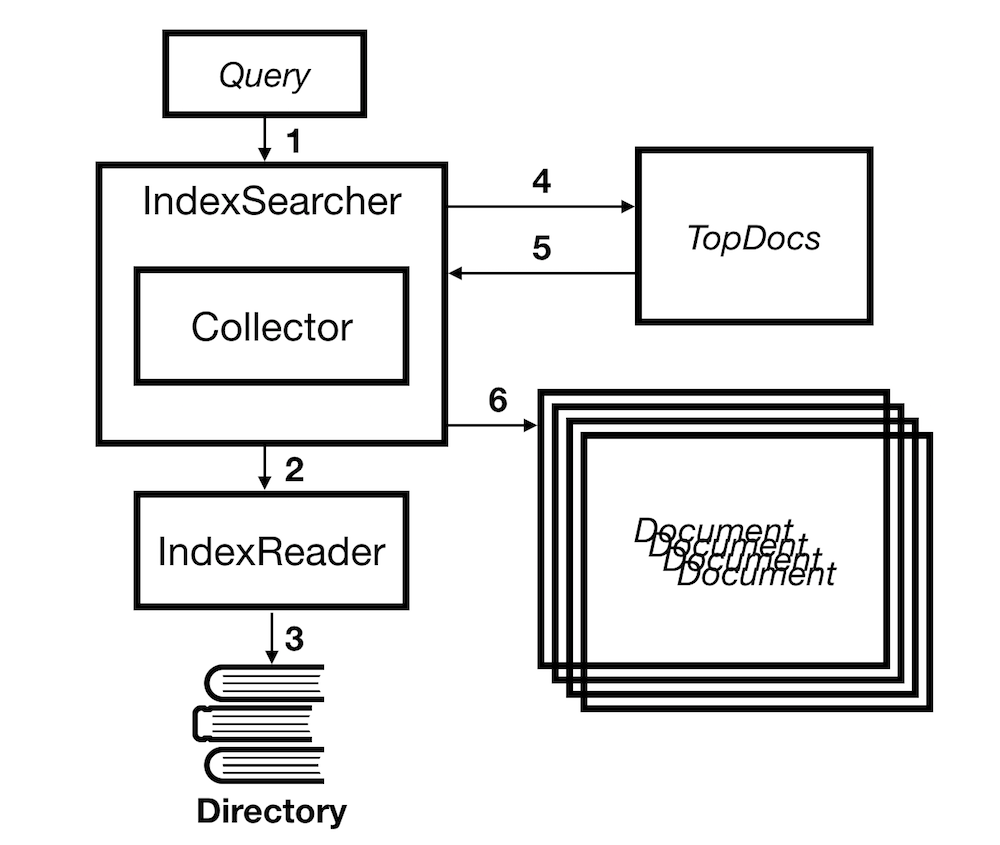
Queryis passed off to theIndexSearcher- The
IndexSearcheruses theIndexReaderto extractTermsfrom the index to match against theQuery. - The
IndexReaderreads the index from theDirectoryin which the index is stored. ReturningTermsfrom the index for the caller to use. - The
IndexSearcherreturns aTopDoc’s object containing the document id for the top matches for the query collected by theIndexSearcher’sCollector. - Finally the Full document is fetched from the index using the
IndexSearcher.
Not all the fields added to the Document before indexing are returned afterwards.
In order to keep index sizes down, only specified StoredFields survive the
indexing process. The rest of the fields are lost when they run through the
analyzers.
Did you find what you are looking for?

Search is a super hard domain, while Lucene may come across as very complicated. It is as simple as it can without sacrificing performance and scalability, which is quite a feat in itself. Apache Lucene has been used to power search experience for Twitter and Linkedin. Remaining flexible enough to be the basis of some genuinely unique search experiences while still being able to scale to millions of users.
While our use case is not nearly as complicated nor demanding. It’s good to know that the basis of our search can take us wherever we might wish to go in the future.